Abstract
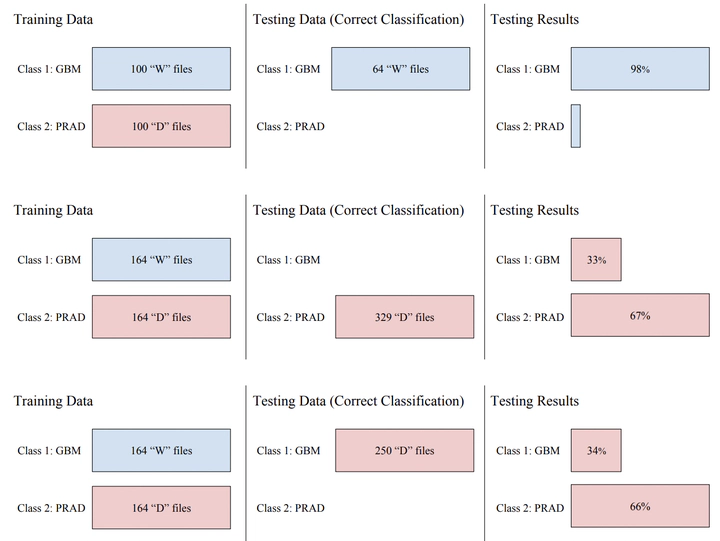
The current paradigm in data science is based on the belief that given sufficient amounts of data, classifiers are likely to uncover the distinction between true and false hypotheses. In particular, the abundance of genomic data creates opportunities for discovering disease risk associations and help in screening and treatment. However, working with large amounts of data is statistically beneficial only if the data is statistically unbiased. Here we demonstrate that amplification methods of DNA samples in TCGA have a substantial effect on short tandem repeat (STR) information. In particular, we design a classifier that uses the STR information and can distinguish between samples that have an analyte code D and an analyte code W. This artificial bias might be detrimental to data driven approaches, and might undermine the conclusions based on past and future genome wide studies.
Bijan Mazaheri
Postdoctoral Associate
My interests include mixture models, high level data fusion, and stability to distribution shift - usually through the lense of causality.