Identification of Mixtures of Discrete Product Distributions in Near-Optimal Sample and Time Complexity
Spencer Gordon, Eric Jahn, Bijan Mazaheri, Yuval Rabani, Leonard Schulman
June, 2024
Abstract
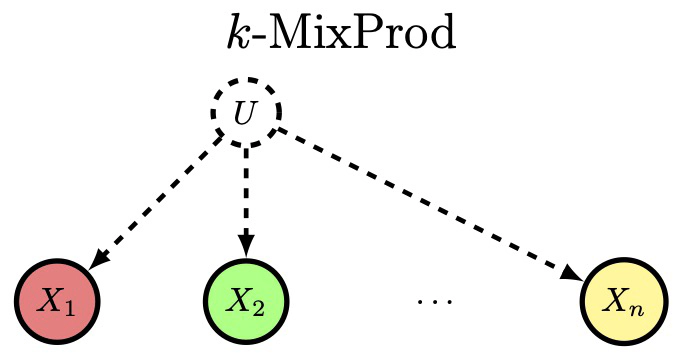
We consider the problem of identifying, from statistics, a distribution of discrete random variables that is a mixture of product distributions. The best previous sample complexity for was (under a mild separation assumption parameterized by ). The best known lower bound was . It is known that is necessary and sufficient for identification. We show, for any , how to achieve sample complexity and run-time complexity . We also extend the known lower bound of to match our upper bound across a broad range of . Our results are obtained by combining (a) a classic method for robust tensor decomposition, (b) a novel way of bounding the condition number of key matrices called Hadamard extensions, by studying their action only on flattened rank-1 tensors.
Publication
In The 37th Annual Conference on Learning Theory

My interests include mixture models, high level data fusion, and stability to distribution shift - usually through the lense of causality.