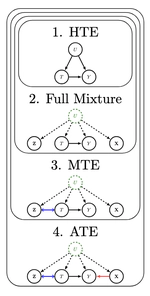
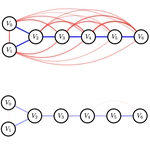
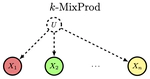
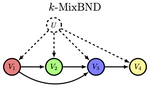
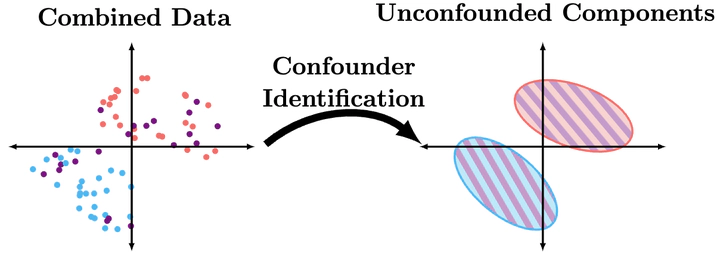
Confounder Identification

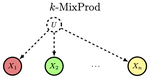
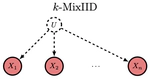
- The
- The
- The
The
We have contributed to complexity improvements on all three steps of this reduction. We have also contributed the first known algorithm for identifying causal structure in the mixture setting.