Causal Information Splitting: Engineering Proxy Features for Robustness to Distribution Shifts
Abstract
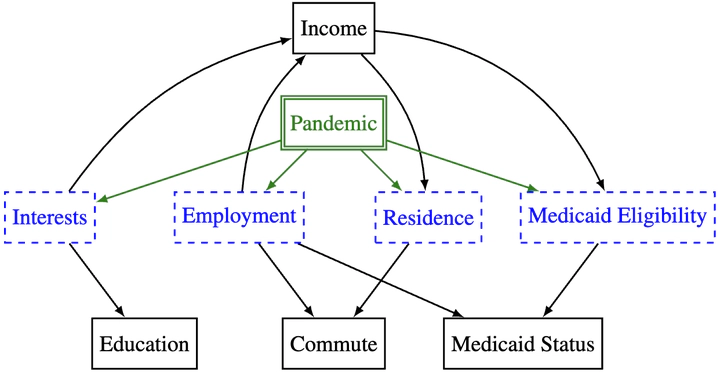
Statistical prediction models are often trained on data from different probability distributions than their eventual use cases. One approach to proactively prepare for these shifts harnesses the intuition that causal mechanisms should remain invariant between environments. Here we focus on a challenging setting in which the causal and anticausal variables of the target are unobserved. Leaning on information theory, we develop feature selection and engineering techniques for the observed downstream variables that act as proxies. We identify proxies that help to build stable models and moreover utilize auxiliary training tasks to answer counterfactual questions that extract stability-enhancing information from proxies. We demonstrate the effectiveness of our techniques on synthetic and real data.
Bijan Mazaheri
My interests include mixture models, high level data fusion, and stability to distribution shift - usually through the lense of causality.