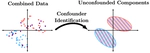
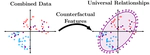
Features often contain a mixture of “good” and “bad” information. From a fairness standpoint, SAT scores contain information about both inherent academic ability, and also access to tutoring resources. From a domain adaptation standpoint, some information may have stable and reliable relationships with the prediction label, while other relationships break down. My work uses insights from causal inference to determine data-representations that sort between the different components of information that are hidden in these ambiguous features.